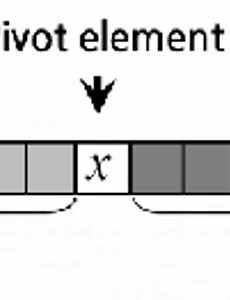
전체 글184 리눅스 3장 - CLI & I/O Redirection - 리눅스 3장- CLI & I/O Redirection - 보통의 PC는 Window의 운영체제를 사용하여 GUI 방식의 명령을 수행한다. GUI는 아이콘을 사용하여 명령을 내리게 되는데 이는 컴퓨터가 많은 에너지를 사용하게 한다. 단순히 생각해도 이미지를 매번 나타내기 때문에 그렇다는 것을 알 수 있다. 이에 비해 CLI는 더 적은 메모리와 CPU를 사용하게 된다. CLI는 명령어를 통해 명령을 수행하는데 명령어를 통해 제어를 하면 순서대로 처리하는 방식에서 큰 장점을 가진다. 이는 속도의 측면에서도 빠르게 작용한다. CLI 방식은 하나의 명령의 실행 결과를 다른 명령의 입력으로 사용할 수 있다. 명령은 프로그램을 가리키게 되고 프로그램은 이에 맞게 프로세스로 바뀌어 수행되게 된다. 명령어를 동시에 수행.. 2017. 6. 8. 머신러닝 실습 with Tensorflow 4장 - Softmax classification - 머신러닝 실습 with Tensorflow 4장- Softmax classification - Softmax는 여러 개의 class를 예측할 때 사용되는 activation function이다. 앞선 장들에서는 sigmoid 함수만을 사용하여 예측을 하였는데 실제로 Output에 해당하는 layer에서는 Softmax를 이용하여 예측하는 경우가 많다. Softmax의 경우 실수로 나타나는 Output의 값들을 확률적으로 나오게 하여 모든 class의 합이 1이 된다. 그렇기 때문에 하나의 output에 대한 확률이 높아질 경우 다른 output에 대한 확률이 낮아지는 현상이 발생하게 된다. 이를 tensorflow로 구현하는 것은 매우 간단하다. 왜냐하면 tensorflow는 머신러닝을 위한 내장 함수를.. 2017. 6. 7. 알고리즘 7장 - 정렬 문제 : 퀵 정렬 - 알고리즘 7장- 정렬 문제 : 퀵 정렬 - 퀵 정렬은 크기가 커서 풀기 어려운 하나의 문제를 크기가 작아서 풀기 쉬운 여러 개의 문제로 바꾸어서 푸는 방법을 사용한다. 이런 방법을 divide-and-conquer paradigm라고 한다. 이를 수행하기 위해 Partitioning을 사용하여 정렬을 한다. Pivot element를 사용하여 Pivot element 왼쪽에는 Pivot 보다 작은 수들을 오른쪽에는 Pivot 보다 큰 값을 가지도록 정렬을 한다. Pivot을 계속 설정하여 위의 과정을 반복하여 수행하면 배열이 오름차순으로 정렬이 되게 된다. 퀵 정렬의 경우 Pivot을 어떻게 잡아서 Partitioning을 수행하는지가 매우 중요한 요건이라고 할 수 있다. 예를 들어 생각을 해보자. 라는.. 2017. 6. 7. 알고리즘 6장 - 정렬 문제 : 힙 정렬(2) - 알고리즘 6장- 정렬 문제 : 힙 정렬(2) - 앞 장에서 힙 정렬에 대한 개념을 알아보았다면 이번 장에서는 힙 구조를 만드는 것에 대해 중점을 두고 힙 정렬에 대해 살펴볼 것이다. 따라서 개념에 대한 부분을 보고자 하면 알고리즘 5장을 보면 될 것이다. Max 힙 구조를 만드는 코드를 한 번 살펴보자. Max 힙 구조는 부모 노드의 값이 자식 노드의 값보다 큰 이진 트리 구조를 나타낸다. Max 힙을 만드는 방법은 위에서 밑으로 만드는 것이 아니라 밑에서 위로 만든다고 할 수 있다. 만약 위에서부터 만들게 되면 밑으로 내려갈 때 마다 Max 힙의 구조를 만족시키는지를 확인해야하지만 밑에서 만들면 밑에서 트리 구조를 만족하는지만 생각하면 되기 때문에 수행 시간에서 단축될 수 있다. 여기서 length의 .. 2017. 6. 7. 리눅스 2장 - file edit(nano) & sudo & Package manager - 리눅스 2장- file edit(nano) & sudo & Package manager - 운영체제에서 파일이라고 하는 것은 정보를 저장하는 아주 기본적인 수단, 저장소라고 할 수 있고 디렉토리는 파일을 잘 정리정돈하기 위한 수납공간이라고 할 수 있다. 앞에서는 파일과 디렉토리를 어떻게 관리할 것인가에 대한 내용이었고 지금은 정보를 파일에 저장하는 방법에 대한 설명이다. 명령어 기반의 시스템에서 편집기로 사용되는 시스템으로는 nano와 vi가 있다. nano의 경우는 처음 리눅스를 사용하는 사람들이 사용하기에 편해서 좋고 vi는 리눅스에서 편집을 하는 것이 편리한 중급자들의 경우 많이 사용한다. 따라서 여기서는 nano에 대한 설명을 해볼 것이다. nano를 터미널에 입력하게 되면 편집기 화면으로 전환된.. 2017. 6. 7. 머신러닝 실습 with Tensorflow 3장 - Logistic regression - 머신러닝 실습 with Tensorflow 3장- Logistic regression - Logistic regression은 Linear regression과 다르게 결과를 0과 1로 나타낸다. 이 때 사용하는 함수는 sigmoid 함수이다. 가설의 형태가 sigmoid 함수로 나타나게 되는데 들어가는 x의 값에 weight이 곱해지는 형태가 된다. cost function의 경우 log를 이용하여 Linear regression과는 다르게 정의를 하게 된다. 하지만 이 cost function 역시 Gradient descent algorithm을 사용하여 최소화를 시킨다. 우리의 아래와 같은 식을 알고 있기 때문에 이를 그대로 tensorflow에 작성만 하면 logistic regression에 .. 2017. 6. 6. 알고리즘 5장 - 정렬 문제 : 힙 정렬(1) - 알고리즘 5장- 정렬 문제 : 힙 정렬(1) - 힙 정렬은 힙 구조의 특성을 이용한 정렬이다. 수행 시간은 작은 형태로 쪼개는 합병 정렬 방법의 수행시간인 O(nlgn)과 동일하고 삽입 정렬과 동일한 제자리 정렬을 한다. 힙의 형태는 완전 이진 트리에 가까운 형태이다. 트리의 형태는 부모 노드와 자식 노드로 이루어져 있는데 부모 노드는 상위에 있는 성분이고 자식 노드는 부모 노드에 연결된 성분을 의미한다. 이는 맨 처음에 존재하는 노드를 제외하고 모든 성분은 부모 노드가 되면서 자식 노드가 될 수 있다. 이진 트리의 경우 각 부모 노드에 연결된 자식 노드의 수가 2이하인 경우를 의미하고 완전 이진 트리는 맨 처음 노드인 Root 노드부터 제일 마지막 노드인 Leaf 노드까지 빠짐없이 채워져 있는 트리를 .. 2017. 6. 6. 알고리즘 4장 - 합병 정렬 - 알고리즘 4장- 정렬 문제 : 합병 정렬 - 정렬 문제는 n개의 숫자들의 배열을 입력으로 받게 되면 입력된 숫자의 배열이 특정 조건을 만족하도록 다시 나열한 결과를 출력으로 나타내는 문제이다. 이번 장에서는 정렬 문제 중에서 합병 정렬에 대해서 학습할 것이다. 합병 정렬은 합병을 이용한 정렬 알고리즘이다. 합병은 두 개의 내용을 합치는 것을 의미한다. 두 개의 정렬된 배열이 주어졌을 때, 정렬된 하나의 배열로 합병을 하는 방법이다. 예를 들어서 과 라는 두 개의 배열이 있다고 가정하자. 각각의 배열들은 오름차순으로 배열이 정렬되어 있다. 이 두 배열을 사용하여 하나의 배열인 으로 정렬을 하는 방법이 합병 정렬이 된다. 여기서 중요한 점은 두 개의 배열이 우선적으로 정렬이 되어 있기 때문에 가장 작은 수가.. 2017. 6. 6. 머신러닝 실습 with Tensorflow 2장 - Multi-variable linear regression - 머신러닝 실습 with Tensorflow 2장- Multi-variable linear regression - 이제 데이터에서 하나의 입력 값이 아니라 여러 개의 입력 값을 받는 Multi-variable linear regression에 대한 tensorflow 실습을 진행할 것이다. 우선 Multi-variable linear regression을 살펴보면 입력 값이 x 하나가 아니라 x1, x2, x3와 같이 여러 개의 입력 값을 받을 수 있고 이에 따른 weight 값이 w1, w2, w3로 존재하게 된다. tensorflow 코드를 이용하게 되면 x1_data, x2_data, x3_data 와 같이 세 개의 데이터를 나누어서 지정을 할 수 있다. 또한 w의 값도 w1, w2, w3를 각각 V.. 2017. 6. 4. 알고리즘 3장 - 정렬 문제 : 삽입 정렬 - 알고리즘 3장- 정렬 문제 : 삽입 정렬 - 정렬 문제는 n개의 숫자들의 배열을 입력으로 받게 되면 입력된 숫자의 배열이 특정 조건을 만족하도록 다시 나열한 결과를 출력으로 나타내는 문제이다. 이번 장에서는 정렬 문제 중에서 삽입 정렬에 대해서 학습할 것이다. 삽입 정렬은 말 그대로 삽입을 이용한 정렬 알고리즘이다. 삽입이라는 것은 어떤 대상을 다른 대상 사이에 넣는다는 말로 어떤 값을 어디에 삽입할 것인가라는 점이 매우 중요하게 된다. Key 값과 정렬된 리스트가 주어졌을 때, key 값을 정렬된 리스트의 알맞은 위치에 삽입을 해야 하는 문제이다. 예를 들어 key 값이 3이고 정렬된 배열이 일 때 키를 알맞은 위치에 삽입한 배열은 으로 정렬이 될 수 있다. 삽입 정렬의 방법은 key 값을 하나씩 추가.. 2017. 6. 4. 이전 1 2 3 4 5 6 ··· 19 다음