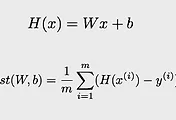머신러닝 실습 with Tensorflow 3장
- Logistic regression -
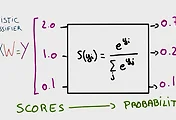
Logistic regression은 Linear regression과 다르게 결과를 0과 1로 나타낸다. 이 때 사용하는 함수는 sigmoid 함수이다. 가설의 형태가 sigmoid 함수로 나타나게 되는데 들어가는 x의 값에 weight이 곱해지는 형태가 된다. cost function의 경우 log를 이용하여 Linear regression과는 다르게 정의를 하게 된다. 하지만 이 cost function 역시 Gradient descent algorithm을 사용하여 최소화를 시킨다. 우리의 아래와 같은 식을 알고 있기 때문에 이를 그대로 tensorflow에 작성만 하면 logistic regression에 해당하는 모델을 만들 수 있을 것이다.

우선 x와 y에 대한 data를 만들어 주어야한다. 이를 간단하게 몇 개의 데이터를 만들어서 넣어주도록 해본다. 실제로 numpy와 같은 자료 모듈들을 사용하여 더 많은 데이터를 가져올 수 있다. 여기서 logistic regression이기 때문에 y_data는 0과 1만의 값을 가지게 된다. x_data는 두 개의 입력 값을 가진다고 가정하면 된다. 이런 데이터 값을 placeholder로 선언된 X와 Y라는 변수에 session을 run 시킬 때 넣어줄 것이다. X와 Y의 shape은 전체의 개수는 임의로 선택되지만 x_data 하나가 가지는 개수와 y_data 하나가 가지는 개수에 따라 X는 2개 Y는 1개라고 할 수 있다. 그리고 weight과 bias에 대한 변수를 만들어 준다. 이때도 shape을 잘 지정해 주어야한다. 들어오는 값의 개수를 앞에 적고 그에 해당해서 나가는 개수를 뒤에 적어주어야 한다. 가설의 경우 위에서 본 sigmoid 함수의 형태로 만들어준다. 실제로 tensorflow에서는 sigmoid 라는 함수로 sigmoid 함수를 바로 사용할 수 있게 해준다.

cost function의 경우도 위에서 알아낸 식을 그대로 코드에 넣어주면 된다. train의 경우 Gradient descent algorithm을 사용하는 것이 같으므로 그대로 작성해주면 된다.

그런데 실제로 sigmoid 함수만을 적용시키게 되면 0과 1이라는 값의 output이 아니라 그 사이의 어떤 값으로 나타나게 될 것이다. 그래서 우리는 그 값을 통해 1로 예측해야 하는지 0으로 예측해야 하는지를 판별해야한다. 그래서 predicted라는 변수를 만들어준다. 이 변수는 cast 라는 함수를 사용하는데 첫 번째 조건(가설 값이 0.5 이상)에 따라 조건에 해당하면 1의 값을 아니면 0의 값을 반환하게 된다. 이렇게 정의된 predicted라는 변수를 accuracy라는 변수를 정의하는데 사용되는데 accuracy는 예측한 predicted라는 값과 실제 결과 값인 Y 값을 equal 이라는 함수를 통해 True와 False로 만들어주고 이를 cast 함수를 통해 True면 1로 False면 0으로 반환하게 된다. 이러한 값들을 평균을 만들어 실제로 가설의 정확도를 따질 수 있게 해주는 변수가 바로 accuracy다.

sess.run을 통해 train을 학습시키게 되는데 X와 Y에 데이터를 넣어준다. 이에 대해 200번마다 cost 값을 출력시켜준다. 그리고 마지막으로 각각의 값에 대한 예측 가설 값과 predicted 값, accuarcy 값을 출력 해보아 학습이 잘 되었는지를 판별할 수 있다.