머신러닝 실습 with Tensorflow 6장
- MNIST data test -
이번 장에서는 Tensorflow에서 머신러닝 모델을 구축할 때 가장 많이 data set으로 사용되는 MNIST을 이용하여 학습시켜볼 것이다. MNIST data는 0부터 9까지 적혀있는 숫자를 나타낸다. 하지만 이 숫자들의 모양이 조금 제각각이다. 하지만 사람의 눈으로 보았을 때에는 딱 봐도 무슨 숫자인지 알 수 있을 정도의 차이이다. 그렇다면 이런 data를 컴퓨터에 넣어주어 학습을 시키면 새로 적은 숫자에 대해 그 숫자가 무엇인지를 맞출 수 있을까? MNIST data set을 가지고 하는 모델 학습은 이것을 목표로 한다.

MNIST data set은 28*28*1 의 픽셀의 이미지로 만들어진다. 그러므로 28*28개의 data input 값을 가지고 있는 것이다. output에 대한 값으로는 0부터 9사이의 값을 나타내니 10의 크기를 가지게 될 것이다.

MNIST data set을 사용하기 위해서 다음과 같은 명령어를 입력해준다. 이는 tensorflow에서 제공해주는 data set이기 때문에 쉽게 가져와서 사용할 수 있다. data를 가져올 때 one_hot이라는 조건을 사용해서 하나의 값만을 가지게 하는 데이터의 형태로 가져온다. X와 Y에 대한 값을 지정해주고 shape은 앞에서 말한 형태처럼 x는 28*28 = 784 개로 y는 nb_classes인 10개로 나타내어 준다.

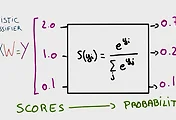
이 후 예측 모델 가설이나 cost function, optimizer, is_correct, accuracy 에 대한 값들은 앞 장의 예측 모델의 tensorflow 코드와 동일하게 나타난다. softmax를 activation function으로 사용하여 가설을 만들었고 이에 대한 cost function과 gradient descent algorithm이 적용된 optimizer가 나타나게 된다. 실제 앞의 예시들에서는 train이라는 값을 다시 만들었지만 여기서는 minimize을 동시에 작동시켜 optimizer로 작동을 마무리한다. 이후 test model인 is_correct와 accuracy를 만들어 사용한다.

여기서 batch와 epoch라는 도구를 사용하는데 batch는 data set의 크기가 클 때 원하는 크기만큼 잘라서 메모리에 올려주는 역할을 수행한다. 여기서 batch의 크기를 100이라고 하면 x data와 y data를 100개씩 나누어서 학습 시켜주게 되는 것이다. epoch는 전체 data set을 몇 번 학습시킬지에 대한 결정이다. 전체 data set을 한 번 학습시킬 때를 1 epoch이라고 한다. 우리의 예시에서는 epoch의 크기는 15이고 batch_size는 100이다. 그러면 100개씩 나누어서 전체 data set을 15번 학습시킨다는 것을 의미한다. total_batch는 전체 데이터를 batch_size로 나누어서 그 값만큼 돌리게 되면 100개씩 나누어서 전체 data를 한 번 돌릴 수 있을 것이다. 이를 다시 epoch size만큼 반복하면 전체 data set을 epoch 번 돌릴 수 있게 된다. mnist.train.next_batch(batch_size)라는 함수를 통해 전체 데이터에서 100개씩 가져와서 사용할 수 있다.

accuray에 대한 값은 test data를 통해서 할 수 있다. eval() 이라는 함수는 sess.run을 했을 때와 같은 결과를 나타내어 주는 함수이다.

이제 실제 데이터를 예측하는 code를 살펴보자. MNIST data 중에서 임의의 random 데이터를 가져온다. 이 data를 학습된 예측 모델에 넣어보고 실제 label의 값과 비교하여 맞는지를 알아본다.

'머신러닝' 카테고리의 다른 글
| 머신러닝 실습 with Tensorflow 8장 - ReLu & Dropout & Xavier - (0) | 2017.06.12 |
|---|---|
| 머신러닝 실습 with Tensorflow 7장 - Neural Network for XOR problem - (0) | 2017.06.11 |
| 머신러닝 실습 with Tensorflow 5장 - training-test data set & learning rate & normalization - (0) | 2017.06.08 |
| 머신러닝 실습 with Tensorflow 4장 - Softmax classification - (0) | 2017.06.07 |
| 머신러닝 실습 with Tensorflow 3장 - Logistic regression - (0) | 2017.06.06 |