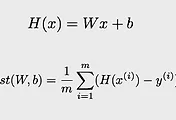머신러닝(Machine Learning) 14장
- 딥러닝 weight 초기화의 중요성 -
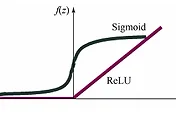
처음 딥러닝을 학습시킬 때 임의의 Weight 값을 넣게 된다. Weight이라는 값은 학습에 의해 계속 값을 바꾸어 가며 Cost function이 가장 작은 값을 가지게 하는 weight 값을 나타나게 된다. 그런데 같은 구조의 딥러닝을 실행시켜도 weight 값의 초기 값에 따라 cost function의 값을 최소화시키는데 걸리는 시간과 데이터의 수가 다르게 나타날 수 있다. 다음의 모델들은 sigmoid와 ReLU의 함수를 사용한 각각의 데이터 모델을 나타내는데 ReLU의 경우 하나의 모델은 바로 cost function이 최소화 되는 과정을 가는 반면에 다른 모델은 더 많은 데이터가 들어가야만 최소화가 되는 것을 알 수 있다. 이러한 차이는 Weight의 초기 값에 의해 차이를 나타나게 된다.

weight 값을 random으로 주게 되었을 때 만약 0의 값을 가진다고 생각을 해보자. w 값이 0이 되므로 만약 Neural Network에서 backpropagation을 통해 학습할 때 편미분 값에 의해 입력 값에 대한 영향을 계산하게 되는데 w가 0이므로 그에 해당하는 x의 값들은 그리고 이 x 값을 결과 값으로 만들어내는 앞의 layer들의 결과들에 대한 편미분 값은 모두 0으로 계산되어 영향을 끼치지 않는 것으로 계산되게 된다. 이렇게 되면 실제로는 영향을 끼치는 데이터인데도 w의 초기 값에 의해 영향을 끼치지 않는 데이터로 학습이 되어 cost function을 최소화시키는 과정이 어려워 질 수 있다.
따라서 weight의 초기화를 잘 시키는 것이 중요하다. 우선 모든 weight의 값은 0을 가지게 되면 안 된다. 앞에서 예시를 들었지만 0을 가지게 되면 입력 값의 데이터가 무시될 수 있기 때문이다. 그리고 더욱 좋은 초기화를 시키기는 방법으로 RBM(Restricted Boatman Machine)이 존재한다. weight를 조절하는 방법으로 Forward한 방법과 Backward한 방법을 비교하는 방법이다. 처음 input 값을 통해 결과 값을 만들어내고 결과 값을 반대로 계산해서 input 값을 만들어낸다. 두 개의 input 값을 비교해서 같게 만들어 주는 weight 값을 찾아 학습을 하는 것이다. 이는 두 개의 layer 사이의 weight 값을 비교하게 되어 학습을 하므로 계속 layer를 넘어가면서 학습을 하게 된다. 그러면 이렇게 만들어진 weight 값을 초기 값으로 가지게 하여 Neural Network 모델을 학습하게 되는 것이다.

그런데 이 방법이 매우 복잡하게 작동하므로 더 쉬운 방법으로 좋은 초기 값을 넣을 수 있는 방법이 나타난다. He’s initialization이라는 이름으로 입력의 개수와 출력의 개수에 따라 적절한 초기 값을 지원해주는 방법이다. weight의 값을 random으로 주긴 하지만 매우 적절한 초기 값을 주는 도구이다.
'머신러닝' 카테고리의 다른 글
| 머신러닝 실습 with Tensorflow 1장 - linear regression - (0) | 2017.06.03 |
|---|---|
| 머신러닝(Machine Learning) 15장 - ConvNet(Convolutional Neural Network) - (0) | 2017.06.02 |
| 머신러닝(Machine Learning) 13장 - ReLU function - (0) | 2017.06.01 |
| 머신러닝(Machine Learning) 12장 - XOR 문제 딥러닝으로 풀기(Backpropagation) - (0) | 2017.05.30 |
| 머신러닝(Machine Learning) 11장 - 딥러닝(Deep Learning) 기본 개념 - (0) | 2017.05.29 |