머신러닝(Machine Learning) 9장
- Learning rate, data preprocessing, overfitting -
Linear regression이나 logistic regression의 방법을 사용할 때 cost function을 최소화시키기 위해서 우리는 Gradient descent algorithm을 사용했다. Gradient descent는 기울기의 크기가 줄어드는 쪽으로 가는 것이 cost function이 최소가 되는 지점을 찾아간다는 생각에서 나온 알고리즘이다. Gradient descent algorithm을 사용할 때 cost 값의 미분한 값 앞에 알파라는 값이 오게 되는데 이 값이 Learning rate이다. Learning rate은 어느 정도의 크기로 기울기가 줄어드는 지점으로 이동하겠는가를 나타내는 지표이다. 그래프 상에서 이동하게 만드는 step의 크기를 조절한다고 할 수 있다. 만약 Learning rate의 값이 크다면 어떻게 될까? 처음 출발에는 기울기가 줄어드는 지점으로 이동을 하겠지만 어느 지점에서 최솟값에 도달하기 보다는 그 값을 넘어서 그래프의 반대편으로 지점이 이동할 수 있다. 이건 step의 간격이 너무 커서 발생하는 결과이다. 또한 이러한 차이가 계속 발생하게 되면 오히려 최솟값에 도달하기 보다는 그래프를 벗어나는 결과 값을 가지게 만들 수도 있다. 이러한 경우를 overshooting이라고 한다.

반대로 Learning rate의 값을 매우 작게 둔다면 어떻게 될까? 그러면 step의 간격이 매우 작게 된다는 것이다. 그러면 학습을 하는 과정에 속도가 매우 느리게 될 것이다. 만약 data를 학습하는 과정의 반복이 적을 경우 최솟값에 도달하기도 전에 학습이 끝나서 원하는 최솟값을 가질 수 없게 된다. 학습을 하고 있는 과정에도 cost 값이 거의 변하지 않는다면 Learning rate의 값이 매우 작다는 것을 의심해 봐야한다. 따라서 Learning rate을 매우 적절하게 적용시키는 것이 매우 중요하다. 실제로 대부분의 Learning rate의 값은 시작을 0.01로 시작해서 overshooting이 일어나면 Learning rate의 값을 줄이고 학습 속도가 매우 느리다면 Learning rate 값을 올리는 방향으로 학습을 진행하면 될 것이다.

Preprocessing은 선처리를 하는 것을 의미한다. 만약 입력 값이 두 개가 존재하는데 값에 대한 범위의 차이가 매우 크다고 생각을 해보자. 원래의 적절한 값을 가지게 되면 다음과 같은 동고선의 형태로 그래프가 나타나게 된다. 3차원의 그래프를 2차원적으로 표현한 것이며 z라는 축으로 cost의 값이 있다고 생각하면 된다. 따라서 가운데 지점이 가장 들어가 있는 부분으로 기울기가 가장 낮게 된다.

그런데 x1과 x2에 대한 값이 거의 1000배 이상 차이가 나타나게 되면 등고선의 형태가 한쪽으로 매우 외곡이 된 형태의 그래프가 나타나게 된다. 그래서 Gradient descent algorithm을 사용하게 되면 한 축으로는 간격이 매우 좁기 때문에 Learning rate가 조금만 커도 다른 방향으로 뛰어나가게 된다. 그러면 우리가 원하는 최솟값에 도달할 수 없게 된다. 이를 방지하기 위해 Preprocessing이라는 선처리 방법을 사용하게 된다. 전체 값의 범위가 항상 원하는 특정 범위 안에 들어가도록 데이터의 값을 수정하게 되는 것이다.



방법은 매우 간단하다. x의 값을 평균과 분산의 값을 이용하여 범위를 줄이게 되어 표준화를 시키는 것이다. 밑은 파이썬을 이용한 식을 나타낸다.

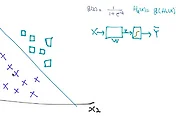
머신러닝에서 가장 중요한 문제는 overfitting이다. 머신러닝은 학습에 의해 데이터를 예측하게 되는데 training data set에 너무 맞게 모델을 맞추게 되면 overfitting이 발생하게 된다. overfitting이 발생하면 training data set에는 매우 맞는 모델이 구축되나 다른 test data나 실제 data를 사용하게 되면 예측에 틀리는 경우가 발생하게 된다. 밑의 두 그래프를 비교해보면 실제로 선형에 의해 오른쪽 위와 왼쪽 아래를 경계로 나누어 볼 수 있다. 그런데 학습한 데이터에 매우 맞는 학습을 하게 되는 경우 오른쪽의 그래프와 같이 overfitting이 발생할 수 있다. 하지만 현실 data와 같은 경우에는 왼쪽의 그래프와 맞는 경우가 매우 많을 것이다. 따라서 왼쪽 그래프가 조금 더 적절한 예측 모델이라고 할 수 있다.

Overfitting을 줄이는 방법으로는 training data를 매우 늘리는 것이다. training 해야 할 데이터가 많게 되면 정확하게 모든 데이터에게 맞는 그래프가 도출되지 않기 때문이다. 다음은 features의 수를 줄이는 것이다. 마지막 방법은 Regularization으로 일반화를 시키는 방법이다. 이는 기술적인 방법인데 weight의 값을 매우 크게 가지지 않게 만드는 방법이다. weight의 값이 커지게 되면 그래프의 형태가 구부러진 형태가 발생하고 weight의 크기가 줄어들게 되면 선형적인 모습을 많이 띄게 된다. 이를 사용하는 방법으로 cost function에 뒤에 regularization하기 위한 식을 추가시켜준다. 모든 weight값에 제곱을 한 값을 더하게 되면 cost function을 통해 최소화되는 값을 찾게 될 것이고 weight 값이 작은 값을 가지도록 설계가 될 것이다.

'머신러닝' 카테고리의 다른 글
| 머신러닝(Machine Learning) 11장 - 딥러닝(Deep Learning) 기본 개념 - (0) | 2017.05.29 |
|---|---|
| 머신러닝(Machine Learning) 10장 - Training-Testing data set - (0) | 2017.05.29 |
| 머신러닝(Machine Learning) 8장 - Softmax regression의 cost함수 - (0) | 2017.05.25 |
| 머신러닝(Machine Learning) 7장 - Multinomial classification - (0) | 2017.05.25 |
| 머신러닝(Machin Learning) 6장 - Logistic Regression 의 cost function - (1) | 2017.05.24 |