Autoencoder & Generative adversarial network
Neural network가 이미지를 만들 수 있다면, classification을 하는 것은 자연스럽게 따라오는 일이다. Unsupervised learning은 label을 가지고 있지 않는 데이터를 학습하는 모델로 데이터의 특징을 모델이 직접 추출하여 판단하는 것을 말한다. Unsupervised learning에서 이미지를 만드는 모델로 대표적인 것이 autoencoder model과 GAN 모델이다.
Autoencoder 모델은 이미지를 생성하기 위해 input과 똑같은 이미지를 label로 하여 network를 학습시키는 모델이다. Encoder부분과 Decoder 부분으로 나뉘어져 있으며 가운데 bottleneck 부분을 가지고 있다. 이미지의 특징을 추출한 후, 특징을 바탕으로 다시 이미지를 만들어낸 과정을 나타낸다. 하지만 autoencoder 모델을 학습할 때 mean square error를 loss function으로 사용하게 되는데 mean 값을 사용하기 때문에 결과적으로 생성된 이미지가 blur하게 나타날 수밖에 없다. 따라서 autoencoder 모델을 실제로 이미지를 똑같이 생성하기 보다는 feature를 뽑아내는 모델, 즉 bottleneck을 얻기 위한 모델로 많이 사용이 된다.


GAN model은 generator와 discriminator로 구성이 된다. Gaussian noise를 가지는 input이 generator를 통과하게 되면 우리가 원하는 image를 생성하게 되고 이를 discriminator가 구분을 함으로써 generator가 더 닮은 이미지를 만들어내도록 학습을 시키게 된다. 논문에 의하면 위의 과정을 경찰과 지폐위조범을 예시로 설명하고 있다. Generator를 지폐위조범으로 discriminator를 경찰로 생각하게 되면 지폐위조범은 위조 지폐를 만들어낸다. 처음에는 위조 지폐를 잘 못 만들어내서 경찰이 쉽게 구별을 하여 처벌을 준다. 그러면 처벌받은 지폐위조범은 처벌을 피하기 위해 더욱 정교하게 위조 지폐를 만들게 된다. 계속 같은 과정을 반복하게 되면 나중에는 지폐위조범이 너무나 닮은 지폐를 만들어내게 되어서 경찰이 구분을 할 수 없게 된다.
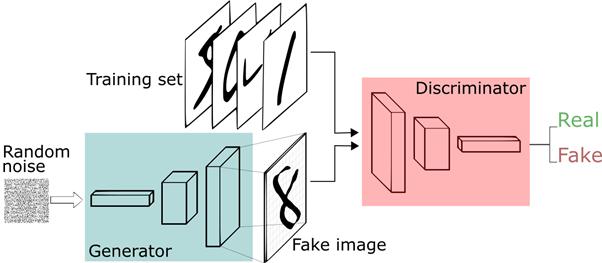
Image credit: Thalles Silva
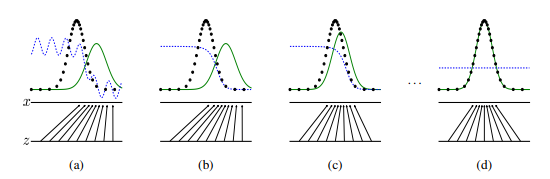
파란색 라인은 discriminator가 fake인지 real인지를 구별하는 정도이고 검은색 라인은 원래 이미지의 분포, 초록색 라인은 generator가 만들어낸 이미지의 분포를 나타낸다. 첫번째에서는 검은색 라인과 초록색 라인이 같이 않기 때문에 discriminator가 real과 fake를 잘 구분한다. 하지만 학습을 거듭할수록 두 분포가 같아져서 discriminator가 구분을 못하고 반반의 확률을 나타내게 된다.
Generator를 학습시키기 위한 수식(loss function)은 다음과 같다.
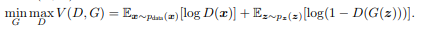
D(x)는 real image가 들어왔을 때 discriminator가 real로 구분을 할 확률이다. D(G(z))는 G에 의해서 만들어진 fake image가 들어왔을 때 discriminator가 real로 구분을 할 확률이다. 위를 해석하기 위해서 극단적인 예시를 넣어보도록 하자. 만약 discriminator가 아주 구분을 잘 한다고 생각을 해보면 D는 real이 input으로 오면 1을, fake image가 오면 0을 나타낸다. 따라서 앞의 수식은 0을 뒤에 수식도 0이라는 값을 나타내게 된다. 만약 discriminator가 구분을 아예 못해서 50% 확률이라고 하면 앞의 수식은 -1, 뒤의 수식도 -1로 합이 -2라는 값을 가지게 된다. Generator 입장에서는 위의 수식 값을 minimize하는 방향이 discriminator를 속이는 방법이기 때문에 값을 낮추려고 학습을 하고 discriminator는 수식 값을 maximize하는 방향이 잘 구분을 할 수 있게 하는 것이기 때문에 그 방향으로 학습하려고 한다.
reference
https://lilianweng.github.io/lil-log/2018/08/12/from-autoencoder-to-beta-vae.html
[Generative Adversarial Nets] (Ian Goodfellow’s breakthrough paper)
'머신러닝' 카테고리의 다른 글
| Deep photo style transfer (0) | 2019.07.18 |
|---|---|
| Single Image Super-Resolution with Convolutional layers (0) | 2019.07.10 |
| 머신러닝 실습 with Tensorflow 8장 - ReLu & Dropout & Xavier - (0) | 2017.06.12 |
| 머신러닝 실습 with Tensorflow 7장 - Neural Network for XOR problem - (0) | 2017.06.11 |
| 머신러닝 실습 with Tensorflow 6장 - MNIST data test - (0) | 2017.06.09 |



