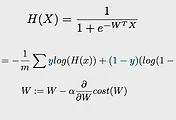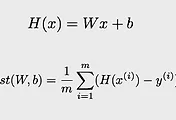머신러닝 실습 with Tensorflow 2장
- Multi-variable linear regression -
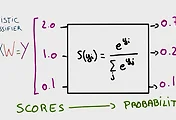
이제 데이터에서 하나의 입력 값이 아니라 여러 개의 입력 값을 받는 Multi-variable linear regression에 대한 tensorflow 실습을 진행할 것이다. 우선 Multi-variable linear regression을 살펴보면 입력 값이 x 하나가 아니라 x1, x2, x3와 같이 여러 개의 입력 값을 받을 수 있고 이에 따른 weight 값이 w1, w2, w3로 존재하게 된다.
tensorflow 코드를 이용하게 되면 x1_data, x2_data, x3_data 와 같이 세 개의 데이터를 나누어서 지정을 할 수 있다. 또한 w의 값도 w1, w2, w3를 각각 Variable을 통해 정의할 수 있게 된다. 값은 random으로 주어지게 되고 크기는 1을 가지게 된다. hypothesis에 대한 값은 w와 x 값을 각각 곱한 다음의 형태로 만들어지게 된다.

cost function과 Gradient descent algorithm을 사용하는 방법은 앞에서 하나의 입력 값에 대한 linear regression과 같은 방식으로 진행할 수 있다. 여기서 learning rate을 조절하여 성능을 다르게 만들 수 있다. learning rate에 대한 이야기는 이론 시간에도 하였지만 값을 너무 높게 주게 되면 발산할 수 있게 되고 너무 작게 주면 최솟값의 cost에 도달하기도 전에 학습이 종료될 수도 있다. 따라서 적절한 learning rate을 지정해줄 필요성이 있다. for 구문을 통해 학습을 진행하게 되고 이 식에서는 cost의 값과 예측되는 값을 저장하여 10의 배수 번째마다 출력을 해주는 작업을 진행한다. 이 때 feed_dict로 앞의 데이터를 넣어준다. 처음에는 cost의 값이 크지만 학습을 진행하면서 cost 값이 작아지는 것을 관찰할 수 있을 것이다. 또한 예측되는 값도 실제 y값과 비슷하게 맞아가는 것을 확인할 수 있다.

하지만 각각의 x데이터를 나열하게 되면 엄청나게 많은 x 데이터에 대해서 사용할 경우 코드의 길이가 커져서 매우 복잡하게 보일 수 있다. 따라서 행렬의 형태를 이용하여 x 데이터 값을 하나의 행렬로 만들어주면 보기에 좋고 간단한 코드만으로 예측 학습을 진행할 수 있게 된다. 여기에서 중요한 점은 shape을 잘 지정해 주어야한다. X와 Y의 데이터를 만들 때 shape에서 넣어주는 데이터의 크기는 none으로 지정하지 않지만 하나의 데이터가 가지는 입력 값의 수는 지정해 주어야한다. 이 값은 w를 지정할 때 입력되는 값으로 사용되기 때문이다. hypothesis를 지정할 때도 행렬의 곱을 이용하여 간편하게 식을 나타낼 수 있다. 이 때 * 기호를 사용하는 것이 아니라 행렬의 곱을 나타내는 matmul이라는 함수를 사용해서 나타내야한다.

'머신러닝' 카테고리의 다른 글
| 머신러닝 실습 with Tensorflow 4장 - Softmax classification - (0) | 2017.06.07 |
|---|---|
| 머신러닝 실습 with Tensorflow 3장 - Logistic regression - (0) | 2017.06.06 |
| 머신러닝 실습 with Tensorflow 1장 - linear regression - (0) | 2017.06.03 |
| 머신러닝(Machine Learning) 15장 - ConvNet(Convolutional Neural Network) - (0) | 2017.06.02 |
| 머신러닝(Machine Learning) 14장 - 딥러닝 weight 초기화의 중요성 - (0) | 2017.06.01 |